
Начало… » Содержание » Учебник по датамайнингу » Том II » Поиск информации в Интернете



«Учебник по датамайнингу»
D.3. Классический датамайнинг в Интернете.
Содержание
D.3.1.1. Специализированные каталоги ресурсов.
D.3.1.5. Специализированные сайты.
D.3.2. Сохранение найденных материалов.
D.3.2.1. Построение дерева каталогов по Вашей теме.
D.3.1. С чего начать поиск?
Итак, Вы сели за компьютер и решили начать поиск в Интернете. Сразу возникает искушение набрать в любимом браузере адрес одной из поисковых систем и... Подождите! Именно так делать не надо. Вначале необходимо:
- Определиться с целями датамайнинга (смотри п. D.2.).
- С помощью интеллект-карт (смотри раздел, посвященный креативному датамайнингу) уточнить область поиска и определиться с источниками информации.
- Собрав эти сведения, приступить к собственно поиску.
Следует отметить, что датамайнинг в Интернете не заменяет, а дополняет оффлайновый датамайнинг. При наличии Интернета еще никто не отменял поиск литературы в журналах, энциклопедиях, в монографиях. Просто сместились акценты этого поиска.
Итак, поиск информации в Интернете можно разделить на:
- Поиск ссылок на статьи и Веб-страницы.
- Поиск ресурсов по данной теме.
(см. интеллект-карту N 1) на рисунке D.02.
При этом не нужно сразу начинать с поиска ссылок (см. Интеллект-карту "Угрозы поиску" на рисунке D.03.). Лучше вначале определиться с доступными для поиска ресурсами.
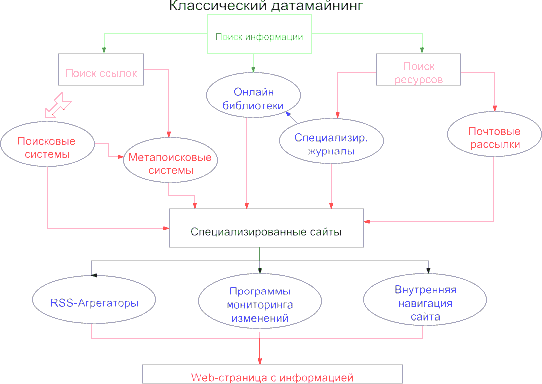
Рис. D.02. Интеллект-карта № 1. Поиск информации в Интернете.
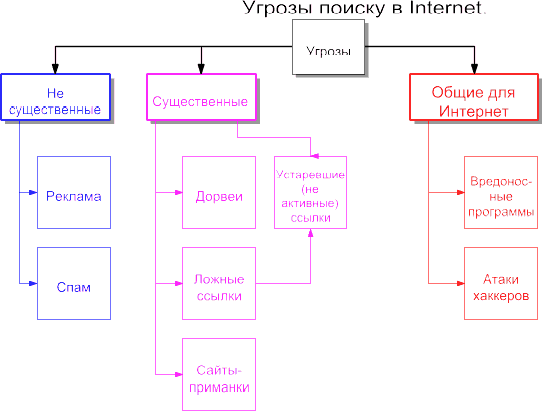
Рис. D.03. Интеллект-карта № 2. Угрозы поиску.
При поиске материала по теме начинать надо с оффлайновых энциклопедий и специализированной литературы (специализированных журналов, газет, рекламно-информационных изданий и т.п.) Если Вы совсем не разбираетесь в теме, по которой Вы собираете материал, то это – лучшее начало для поиска.
Далее советую углубить поиск, уже с использованием Интернет. Во-первых, Вы можете обратиться в онлайновые энциклопедии и библиотеки (список прилагается). Во-вторых, Вы можете читать онлайновые версии обычных журналов (периодики). В-третьих, Вы можете подписаться на почтовые рассылки по Вашей теме. Во всех этих онлайновых ресурсах Вы преследуете две цели:
- Получить полезную информацию (основная цель);
- Найти полезные для Вас ссылки на специализированные сайты (второстепенная цель).
При поиске ресурсов в Интернете необходимо использовать следующие программы:
- Программы-браузеры Интернет.
- Программы для захвата и каталогизации содержимого страниц.
- Программы для захвата и каталогизации ссылок на ресурсы в сети.
- Программы обеспечения безопасности при работе в сети (смотри ссылку на приложение № II здесь).
При поиске ресурсов Вы должны интенсивно работать с программами-каталогизаторами ссылок.
Не пренебрегайте при поиске ресурсов использовать почтовые рассылки, для чтения которых Вам, возможно, потребуется почтовый клиент.
Конечно же, информационная составляющая почтовых рассылок не велика. Но почтовые рассылки позволяют:
- Получить необходимые ссылки не ресурсы, проверенные автором рассылки;
- Получить представление о теме, по которой Вы осуществляете поиск;
- Познакомиться (хотя бы заочно) с автором рассылки и получить обратную связь.
- Вы можете получить рецензию на Ваши материалы у автора рассылки.
Уже одно это позволяет автору рекомендовать почтовые рассылки для использования в датамайнинге. Подписаться на почтовые рассылки можно, например, на сайте Subscribe.Ru.
Важно! При использовании почтовых рассылок Вам может поступать также несанкционированная рассылка ("спам"). Не стоит обижаться на это на автора рассылки – Ваш адрес, может быть, был украден хакерами. Для ликвидации вреда от спама используйте следующие советы:
- Используйте в качестве "публичного" e-mail адреса адрес одного из бесплатных почтовых ящиков.
- Никогда не открывайте подозрительные письма (письма с вложениями от незнакомых адресантов, с пропущенной или подозрительной темой).
- Поставьте на свой компьютер антивирусный пакет и программу защиты от спама.
D.3.1.1. Специализированные каталоги ресурсов.
Как правило, человек, занимающийся датамайнингом длительное время, начинает поиск ссылок не с поисковых систем, а со специализированных каталогов ресурсов. Найти их в Интернете не так уж и сложно. Наиболее знаковые из этих ресурсов можно найти на сайтах, указанных на этой странице. и здесь. Автор приводит лишь следующие примеры:
- Онлайновая библиотека Wikipedia. Содержит множество статей, которые пишут и редактируют сами посетители этой библиотеки. Присутствуют статьи практически на всех языках, в т.ч. и русском (сайт http://www.wikipedia.org/).
- Справочник "Желтые страницы Интернет" (на русском языке). Содержит в себе проверяемый авторами и все время пополняющийся новыми ссылками каталог ресурсов русского Интернета (Рунета). (Сайт http://yp.piter.com/).
- Проект Россия-Он-Лайн: Реферат.Ру. Здесь собрана большая, все время пополняющаяся коллекция рефератов, шпаргалок и курсовых работ по разным тематикам на русском языке. (Сайт http://www.referat.ru/).
Большой каталог тематических ресурсов в Интернет печатается в журнале "ПК-Просто", "PC Magazine/RE" и других.
D.3.1.2. Поисковые системы.
Следующее место, куда следует обратиться в процессе поиска информации – это поисковые системы. В настоящее время поисковые системы – это порталы, где, помимо поиска, располагаются каталоги ресурсов, платежные системы, услуги предоставления бесплатного почтового ящика, бесплатного хостинга или размещения блогов (сетевых журналов). Наиболее популярные поисковые системы приведены на интеллект-карте "Search Systems" ("Поисковые системы"), а предоставляемые ими услуги – на интеллект-карте "Порталы Рунета".
Каталоги поисковых систем могут быть использованы для поиска ссылок специализированных сайтов, когда предметная область поиска "локализована".
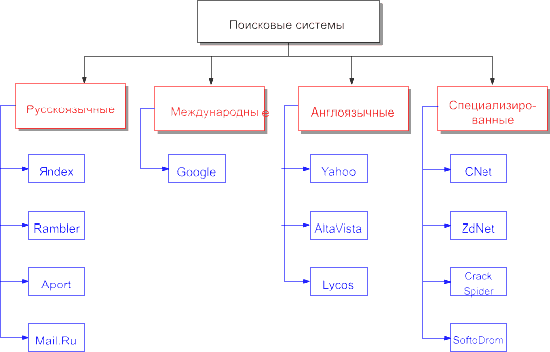
Рис. D.04. Интеллект-карта "Поисковые системы"
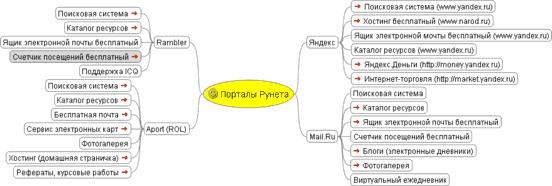
Рис. D.05. Интеллект-карта "Порталы Рунета".
Ознакомиться с этими порталами и узнать их Интернет-адреса можно в приложении № IV здесь.
Следует отметить, что во многом поиску в Интернет помогают метапоисковые системы, такие, как Web Ferret и другие. Принцип их действия показан на интеллект-карте "Meta search system" (смотри рисунок D.06.). Метапоисковая система – это клиентская программа, которые ищет ссылки на специализированные сайты, но не из своей базы или индекса. Она использует индексные базы данных и каталоги других поисковых систем, то есть как бы "паразитирует" на них. Однако, вследствие того, что поиск ведется сразу по нескольким поисковым системам, отдача (количество найденных ссылок) у метапоисковых систем будет больше, чем у обычных поисковых машин.
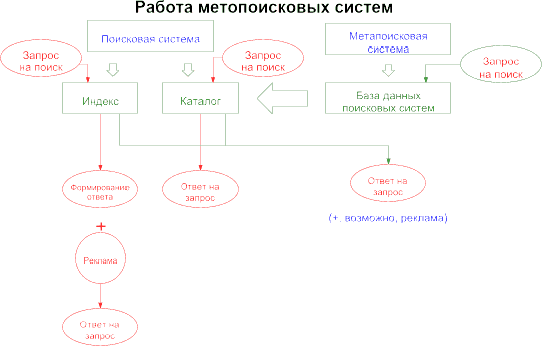
Рис. D.06. Принцип работы метапоисковых систем.
D.3.1.3. Почтовые рассылки.
Как уже отмечалось в п. D.3.1, подзаголовок «Поиск ресурсов», необходимым средством для датамайнинга являются почтовые рассылки. Подписаться на почтовые рассылки можно, например, на сайте "Subscribe.Ru" (адрес сайта http://www.subscribe.ru/). На этом сайте находится множество разделов, в которых можно выбрать рассылку на любой вкус. При регистрации на этом сайте Вы сразу же становитесь подписчиком рассылки: "Новости Subscribe.Ru", в которой дается анонс новых рассылок, дискуссионных листов и новостей сайта.
Свои подписки имеют многие известные порталы. Например, обзоры книг, информацию о компьютерных курсах, новых поступлениях в онлайновую библиотеку можно узнать из подписки на сайте Цит Форум (адрес сайта "http://www.citforum.ru/"). Во многом подписка на этих сайтах заменяет в использовании новых программ: RSS-агрегаторов.
D.3.1.4. RSS-агрегаторы.
Это относительно новое направление в Интернете, позволяющее обновлять информацию на Вашем компьютере. Не секрет, что многие сайты обновляются нерегулярно, и довольно трудно "вручную" обойти все сайты и просмотреть, если новая информация на них. RSS-агрегаторы позволяют сразу после соединения с Интернетом найти на сайте обновления контента и закачать его на Ваш компьютер. К сожалению, обновить информацию можно только на тех сайтах, которые поддерживают RSS-агрегаторы (обычно это указано на главной странице сайта). Если ресурс для Вас представляет ценность, то для получения информации с него обязательно используйте RSS-агрегаторы.
D.3.1.5. Специализированные сайты.
После посещения специализированных каталогов и поисковых систем, Вы наверняка получите ссылки на специализированные сайты с нужной для Вас информацией. Как правило, это будет заглавная страница проекта. Далее Вы будете просматривать сайт, используя его навигацию.
На сайтах, имеющих в своем составе большие объемы информации, имеются специальные инструменты навигации. Перечислим их.
- Информационное меню. Оно существует практически на всех сайтах. Она похожа на страницу "Содержание" на странице справочной системы Windows, и отражает логическую структуру сайта. Пункты меню имеют разную вложенность, поэтому попасть сразу на нужную страницу из информационного меню представляется проблематичным. Если Вы знаете, на какую именно страницу Вы хотите попасть, используйте карту сайта.
- Карта сайта. Карта – это отображение структуры файлов и каталогов сайта, представленное в виде дерева (как в проводнике – Windows Explorer). Используя карту сайта, можно просто и быстро найти нужную страницу с информацией, и вызвать ее одним щелчком мыши. Однако у этого инструмента навигации есть недостаток: если Вы не знаете информационного содержимого и структуры сайта (из информационного меню), найти нужную страницу для Вас по ее имени будет представлять сложности. Следует отметить, что карты есть не у всех сайтов.
- Строка: "Поиск по сайту". Этот пункт представляет собой простую полнотекстовую поисковую систему, с помощью которой можно найти нужные слова или фразы на любой странице сайта. Как правило, эти алгоритмы поиска запатентованы, и поэтому встречаются только на коммерческих сайтах (и то не на всех). Этот инструмент полезен для поиска конкретного контента на сайте.
Примечание. Информационное меню может быть реализовано пот разным технологиям: простой текст, таблица, фрейм, CSS, CGI-меню и т.д. Эти технологии влияют в основном на вид меню и на его время отклика (реакции на щелчки мышью). Поэтому автор дает совет Веб-дизайнерам: меньше времени уделяйте внешнему виду, а больше – наполнению Ваших страниц. Не важно, как выглядит навигационное меню. Важнее, насколько с ним удобно работать.
Примечание. Аналог строки "Поиск по сайту" имеется практически во всех специализированных каталогах и поисковых системах. Они позволяют искать нужные ссылки внутри своего собственного каталога. При этом в поиске участвуют не только тексты ссылок, но и аннотация ресурса в каталоге, его тэги и другая метаинформация о ресурсе.
На специализированных сайтах может присутствовать различная информация в любом виде. Приведем некоторые наиболее распространенные форматы файлов на сайтах:
- HTML-страницы (и их разновидности). В этом формате могут быть представлены статьи и навигация по сайту;
- PDF-документ. В этом формате часто представляются статьи, специально предназначенные для печати на принтере;
- документы Microsoft Office (Word, Excel, PowerPoint, Publisher и т. п.). Эти документы предназначены для правки и печати;
- графические изображения (рисунки, фотографии, схемы в форматах .GIF, .JPEG и .PNG) – для представления не текстовой информации;
- программные продукты (расширение .EXE). В этом формате распространяется большинство демонстраций и обучающих программ;
- архивные файлы (с расширением .ZIP, .RAR, .TAR.Z, .TAR.GZ и др.). Они представляют собой как бы "контейнеры" для передачи файлов или группы файлов любых других форматов;
- другие форматы данных (например, звуковые файлы) используются значительно реже.
Для чтения файлов, скаченных из Интернета, используйте программное обеспечение, работающее с соответствующими форматами данных.
Автор рекомендует для просмотра информации, содержащейся на сайте, следующие программы:
- для чтения гипертекстовых документов: любой современный браузер (Microsoft IE 6.0, Maxton 2.xx, Mozilla FireFox 1.5);
- для чтения PDF-файлов: программа Adobe Acrobat Reader 7.0;
- для чтения документов Microsoft Office: Microsoft Office 97-XP;
- для просмотра графических изображений: Fast Stone Image Viewer, IrfanView, XnView, Wega 2;
- для распаковки архивных файлов – программу WinRAR 3.51.
D.3.2. Сохранение найденных материалов.
Итак, Вы специально или случайно, тем или иным способом нашли необходимую Вам страницу. Вот Вы обозреваете ее довольным и горящим взглядом, и хотите тут же ее сохранить. Но прежде, чем ее сохранить, нужно ответить на следующие вопросы:
- А смогу ли я найти сохраненный документ в течение следующего месяца (дня, часа)?
- Как мне не потерять его при перестановке системы на компьютере?
- Могу ли я его легко восстановить из архива?
Чтобы уверенно ответить на эти вопросы, Вы должны вспомнить правила классического датамайнинга без использования Интернет. Вы, наверное, помните, что автор "что-то говорил" о папках, файлах и конвертах. Применительно к Интернету это будет выглядеть следующим образом.
D.3.2.1. Построение дерева каталогов для Вашей темы.
Все документы по теме необходимо держать в одной папке. Но использование компьютера позволяет хранить документы сразу в нескольких папках, группируя их в зависимости от сложности темы. Использование возможности создавать "деревья папок" очень полезно для Вас, и автор расскажет, как это организовать лучшим образом.
Место расположения корня каталогов.
Корень каталогов с темами для датамайнинга должен начинаться от папки "Мои документы". Преимущества выбора данной папки для корня следующие:
- Все поисковые системы позволяют осуществлять поиск файлов в папке "Мои документы". Для поиска в других местах диска это правило может не работать.
- Папку "Мои документы" легко архивировать.
- Если Вы перенесли папку "Мои документы" с диска C: на любой другой диск, Вам не нужно будет беспокоиться о проблемах с виртуальной памятью, исчерпанием места на диске и потерей данных в результате краха системы. Правила переноса папки "Мои документы" смотри в книге «Самые начала...»
Некоторые пользователи сохраняют свои документы на рабочем столе своего компьютера (вернее, в папке C:\Documents and Settings\<users>\Рабочий стол, где <users> – логин (имя) пользователя при входе в систему). Это делать не желательно по указанным выше причинам.
Далее желательно в папке "Мои документы" создать дочернюю папку с запоминающимся именем (PROJ, DATAMING или др.), куда будете помещать свои проекты, и обязательно выведите ярлык этой папки на рабочий стол! Это сделать желательно, поскольку Вы можете тогда вызывать список Ваших тем для датамайнинга с рабочего стола (это может потребоваться для программ, сохраняющие данные на рабочем столе, например Mozilla FireFox).
После этого можно не беспокоиться о других настройках папки. Все вызовы на архивирование данных, сохранения документов, индексации и поиска файлов будут происходить так же, как и с папкой по-умолчанию: "Мои документы".
Правила построения дерева.
Итак, Вы создали корневую папку, куда Вы будете складывать файлы, полученные из Интернет или отсканированные изображения для датамайнинга. Для каждой темы создайте свою собственную папку. Кроме того, в каждой дополнительной папке Вы должны создать следующие дочерние папки (которые Вы можете назвать по-своему):
.\SOURCE – для хранения исходных файлов датамайнинга (необработанных Вами).
.\SOURCE\IMAGES – для хранения необработанных изображений.
.\WORK – для файлов датамайнинга, подвергшихся Вашей обработке.
.\DEST – для написанных Вами статей по результатам датамайнинга.
Внутри этих папок можно располагать папки с файлами, сгруппированные, например, по расширению, по обрабатывающих их программами и т.п.
Желательно в корневой папке с темой для датамайнинга периодически генерировать дерево каталогов (например, с помощью программы NikFileTree). Это позволит Вам лучше ориентироваться в темах при полном или частичном архивировании папок.
При сохранении файлов датамайнинга в специальных форматах, не забудьте создать папку с дистрибутивами соответствующих программ, обрабатывающих эти файлы. Их лучше всего хранить в папке \Distrib и архивировать ее вместе с файлами датамайнинга.
Формат хранимых файлов.
Вы можете получать из Интернета различные файлы с различными форматами. При переписке Вы также можете использовать различные форматы. Но автор статьи предупреждает: множество форматов данных мешает их обработке. Во-первых, автор вспоминает "бритву Окаммы", которая гласит следующим образом: "Не плоди сущностей сверх меры". При большом количестве форматов файлов с данными Вы можете:
- не уследить за всеми изменениями в файлах с одними и теми же данными;
- потерять программу, которая обрабатывает специфичные данные;
- архивирование редко используемых программ для чтения файлов с данными приводит к большому размеру архива;
- новые версии программы могут не читать старые форматы файлов с данными, а старые версии могут не запускаться в Вашей системе;
- использование для обработки файла определенного формата нескольких разнородных программ часто приводит к их несовместимости и потере данных.
Чтобы избежать этих неприятностей, пользуйтесь следующими правилами:
- Храните все файлы, скаченные из Интернета, и которые не будут правиться, в форматах HTML и PDF.
- Храните все текстовые файлы, с которыми Вы работаете, в формате text/plain (расширение .TXT). Как исключение, текстовые файлы можно хранить в формате любимого Вами текстового процессора.
- Храните данные, полученные из электронных таблиц, в формате Microsoft Excel 97.
- Храните базы данных либо в таблицах Excel, либо в форматах dBase III (они так будут лучше читаться).
- Векторные рисунки храните в формате Вашего любимого графического редактора. Для обмена данными между векторными редакторами используйте формат Windows Meta File (расширение .WMF). С этим расширением файлы обязательно должны находиться в архиве.
- Для хранения растровых графических файлов используйте:
- для фотографий – формат JPEG (иногда допускается RAW);
- для всех остальных рисунков в архиве – формат Portable Network Graphics (расширение .PNG);
- для растровых рисунков, подлежащих дальнейшей обработке в различных редакторах и печати – форматы Windows Bitmap (с расширением .BMP) и TIFF ( с расширением .TIF).
- Для хранения звуковых фрагментов используйте формат .WAV. Для их занесения в архив можно использовать различные алгоритмы их компрессии.
- Скаченный из Интернета видеоряд нужно сразу записать на компакт-диск, вместе с кодеком для его проигрывания.
- Все остальные файлы с данными не являются специфичными для Интернета, поэтому должны храниться только вместе с программами, их обрабатывающими.
Если по каким-то причинам это сделать затруднительно, храните эти папки в подпапках
.\SOURCE\<расширение>
.\WORK\<расширение> ,
где <расширение> – расширение файлов с данными для этих форматов.
D.3.2.2. Использование древовидных баз данных.
Как бы Вы не оптимизировали дерево каталогов ваших файлов, предназначенных для датамайнинга, рано или поздно наступит момент, когда использование такого дерева будет неудобным. Для хранения полнотекстовых документов вместе с их изображениями предназначены древовидные базы данных. Их устройство достаточно просто:
- база данных представляет собой дерево, начинающееся с корня и имеющая в своем составе "ветви" (другие деревья) и "листья" (хранимые документы);
- ветви и листья могут перемещаться по базе данных, гибко меняя свою структуру;
- у каждой базы есть функции экспорта и импорта документов;
- многие базы данных могут быть "интегрированы" с браузерами Интернета;
- кроме опций импорта и экспорта документов, в этих базах есть возможности редактирования текста документа, создания парольного доступа к некоторым ветвям, создание заметок к ветвям, изображения ветвей и документов с помощью индивидуальных иконок и т.п.
База данных Widjsoft MyBase.
Наиболее "продвинутой" и специально предназначенной для классического датамайнинга является программа MyBase. В этой базе данных можно создавать ветви любой вложенности. Программа может импортировать обрабатывать в себе файлы следующих форматов:
- text/plain;
- text/html;
- Rich Text Format.
Встроенный в базу данных редактор может выполнять большинство возможных команд редактирования текста, доступных в текстовых процессорах. Также возможен импорт HTML-страниц вместе с рисунками, скриптами и ссылками.
Очень хорошо реализовано в этих системах создание и отображение перекрестных ссылок внутри базы данных.
Базу данных можно также использовать для создания конспектов и заметок, имеющих вложенные пункты (например, 1., 2., 2.1, 2.2, 3., 3.1., 3.1.1. и т.п.).
В общем, это идеальное средство для классического датамайнинга и ведения конспектов. Огорчает только то, что она распространяется по лицензии Trial ware с испытательным сроком в 40 дней.
Преимущество MyBase состоит также в том, что эти базы данных индексируются локальной поисковой системой Архивариус 3000.
База данных AML Pages.
Что касается второго продукта, то этот продукт не может претендовать на место полноценной древовидной базы данных. У нее нет возможности импорта документа вместе со скриптами и изображениями, более беден и менее удобен интерфейс для редактирования текста и т.п. Кроме того, у этой программы часто бывают "зависания" по невыясненным причинам.
Но эта программа – идеальное средство для ведения древовидных конспектов, имеющих вложенные пункты. С этой целью в программе предусмотрены шаблоны для создания справочников, календарей, списка задач. Кроме всего этого, этот редактор совершенно бесплатен, что позволяет сэкономить средства, если Вам нужен просто древовидный блокнот.
D.3.2.3. Использование локальных поисковых систем.
Использование полнотекстовых локальных поисковых систем, на первый взгляд, выглядит пижонством. Вы можете спросить: "А зачем мне локальные поисковые системы, если я могу выбрать пункт меню "Найти", набрать соответствующий запрос и... ?". В том-то и дело, что встроенный в операционную систему Windows полнотекстовый поиск не является эффективным. По сути это – наследник программы поиска файлов в командной строке find.com . Да, в версии Windows XP имеется полнотекстовый поиск, индексация, фильтры, но все это реализовано не совсем в законченном виде. Итак, встроенный поиск:
- занимает много времени (в основном из-за отсутствия или недостаточной индексации);
- имеют недостаточное число фильтров (используются фильтры на размер файлов, дату их создания и модификации, имя и расширения файлов и т.п.);
- невозможность расширенного поиска контента и использование регулярных выражений;
- невозможность поиска в нескольких каталогах одновременно.
Этих недостатков лишены локальные полнотекстовые поисковые системы. Их особенность состоит в том, что они создают индекс файлов, которые может искать данная поисковая система, расположенных в определенных папках. Благодаря тому, что индексация происходит заранее и тому, что из индекса удаляются лишние папки, поиск в этих системах идет на порядки быстрее. Если Вы правильно организовали систему хранения Ваших документов для датамайнинга, поиск нужных материалов будет происходить за секунды.
Недостаток локальных поисковых систем заключается в том, что при добавлении новых файлов в каталог или при изменении уже существующих файлов необходимо обновлять индексы Ваших поисковых систем. Если Вы не поставили опцию: "Обновлять индекс по расписанию", Вам придется запускать принудительное обновление индекса перед каждым поиском (что сводит на нет его преимущества перед встроенным в Windows поиском).
В этом разделе описываются две локальные поисковые системы, которые автор рекомендует поставить на Ваш компьютер: Copernic Desktop Search и Архивариус 3000. Конечно же, существует множество других подобных систем. Но именно эти две системы дешевы и могут гибко менять настройки специально для Ваших нужд.
Поисковая система Copernic Desktop Search
Данная программа, в общем-то, не является полнотекстовой поисковой системой. Принцип ее использования – создание индекса файлов в указанных каталогах и поиск с его помощью более чем 30 различным фильтрам. Помимо стандартных фильтров (по дате и размеру), программа способна искать:
- музыкальные файлы: по тегам "Исполнитель", "Жанр", "Альбом", год выпуска;
- видеофайлы: по тем же параметрам;
- базы данных почтовых сообщений: по имени адресата, теме сообщения, даты получения/отправки;
- файлы Office – по автору документа, названия работы и т.п.
Кроме того, возможен поиск файлов по указанным шаблонам.
Программа при своей работе сразу выдает список проиндексированных файлов, соответствующих запросу, сразу после введения условий на фильтрах. Любой файл тут же можно просмотреть или воспроизвести (для музыкальных файлов). Также любой файл можно вызвать для редактирования преопределенной для файлов данного типа программой. Недостаток программы – очень плохая поддержка кириллицы.
Поисковая система Архивариус 3000.
Эта поисковая система позволяет осуществлять полнотекстовый поиск по большому числу текстовых документов. Она обладает меньшим набором фильтров, чем поисковая система Copernic Desktop Search, но обладает уникальным механизмом текстового поиска.
Данная программа позволяет:
- использовать стандартный набор фильтров для поиска файлов;
- возможность поиска в тексте по словам, регулярным выражениям и фразам (доступно в режиме расширенного поиска);
- позволяет ранжировать найденные файлы: по точности совпадения запроса, по количеству слов из запроса, встретившемся в файле, по расширению файла, и другие механизмы любого полнотекстового поиска;
- программа имеет встроенный просмотрщик для просмотра найденных файлов в унифицированном интерфейсе;
- осуществлять поиск слов из кириллических символов, даже содержащие ошибки;
- перекодировать символы, написанные транслитерацией;
- вызывать файлы на редактирование одним щелчком мыши;
- быстро создавать и обновлять индекс файлов (правда за счет увеличения размера индекса);
- индексировать почтовые базы данных, списки контактов и другие записи почтовых клиентов;
- позволяет индексировать большинство текстовых форматов, в том числе и древовидные базы данных программы MyBase.
Все это позволяет рекомендовать эту поисковую систему в качестве основной системы для полнотекстового поиска файлов, содержащих кириллические символы.



 .
.